Introducing Key Concepts of AzureML
Objectives
In the following exercise you will learn about the key concepts of the AzureML Service:
- Compute Targtes
- Compute Cluster
- Compute Instances
- Datastores and Datasets
Setting up the Compute Targets
Prerequisites
To run through below instructions, you need an Azure subscription and an Azure ML workspace. See instructions on how to create a workspace here and more details here.
Creating an AzureML compute cluster
We will do a number of actions that require a compute target to be exectuted on. We will start by creating a cluster of CPU VMs.
-
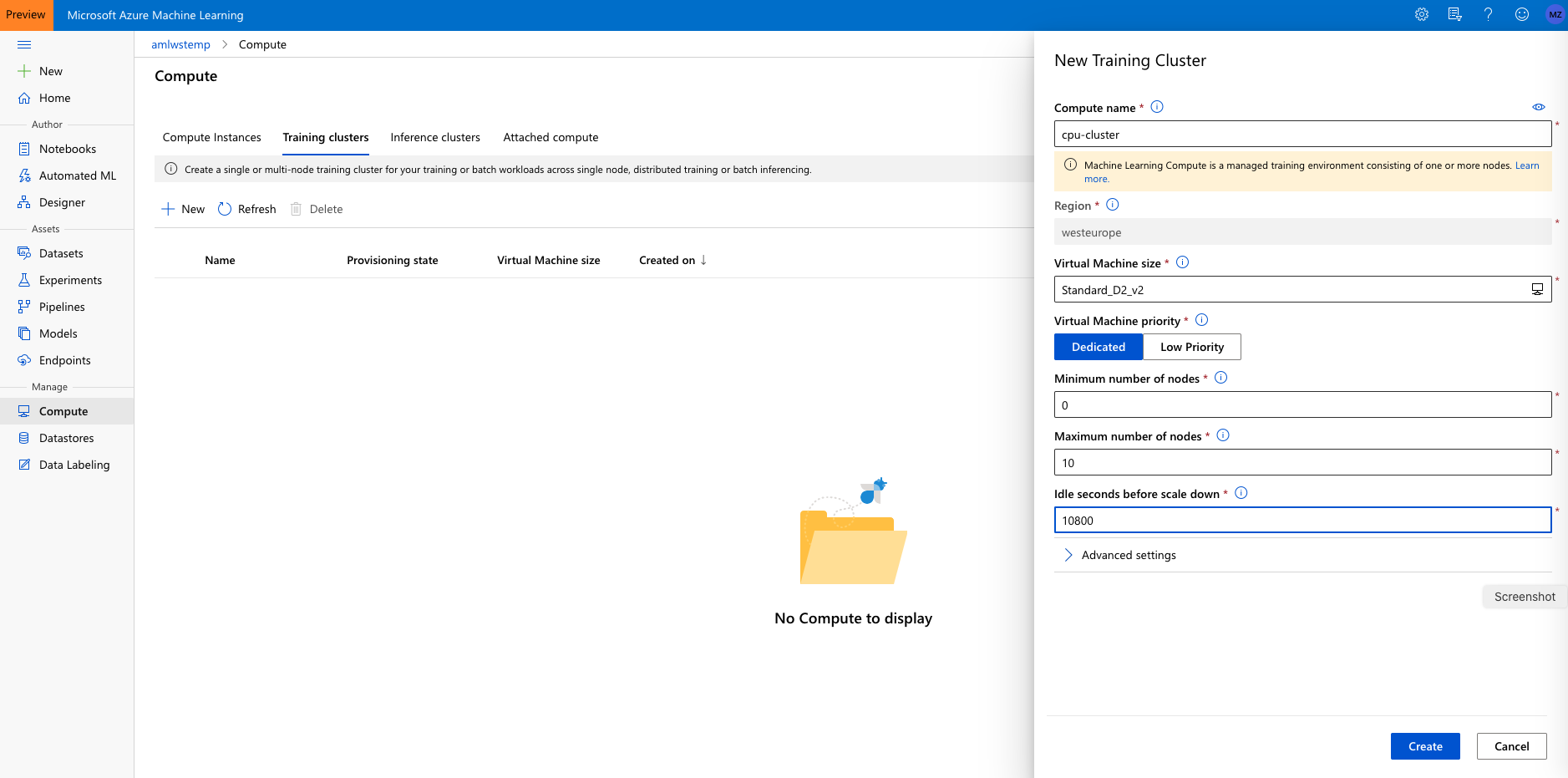
Navigate to ‘Compute’ > ‘Training Clusters’ in the “Manage” section and click ‘New’.
-
Call the cluster ‘cpu-cluster’.
- For machine size choose ‘Standard_DS2_v2’ (that is an inexpensive general purpose VM size at about $0.14/hour). See details about AzureML compute pricing here.
- Set the ‘minimum number of nodes’ to 0 and the the ‘maximum number of nodes’ to 4. That way the cluster will scale automatically to up to 4 nodes as jobs require them.
- Set the ‘Idle seconds before scale down’ to 10800. That means that nodes will be kept around for 3 hours before they are spun down. That way, during our workshop, jobs won’t have to wait for spin-up. Make sure that number is lower if you are using a more expensive VM size.
Creating an AzureML Compute Instance
Next, we will create a compute instance. The compute instance will serve as an interactive workstation in the cloud that serves as a Jupyter server, but also hosts and instance of RStudio server and can run TensorBoard, Bokeh, Shiny or other apps used during the developement work of a data scientist.
-
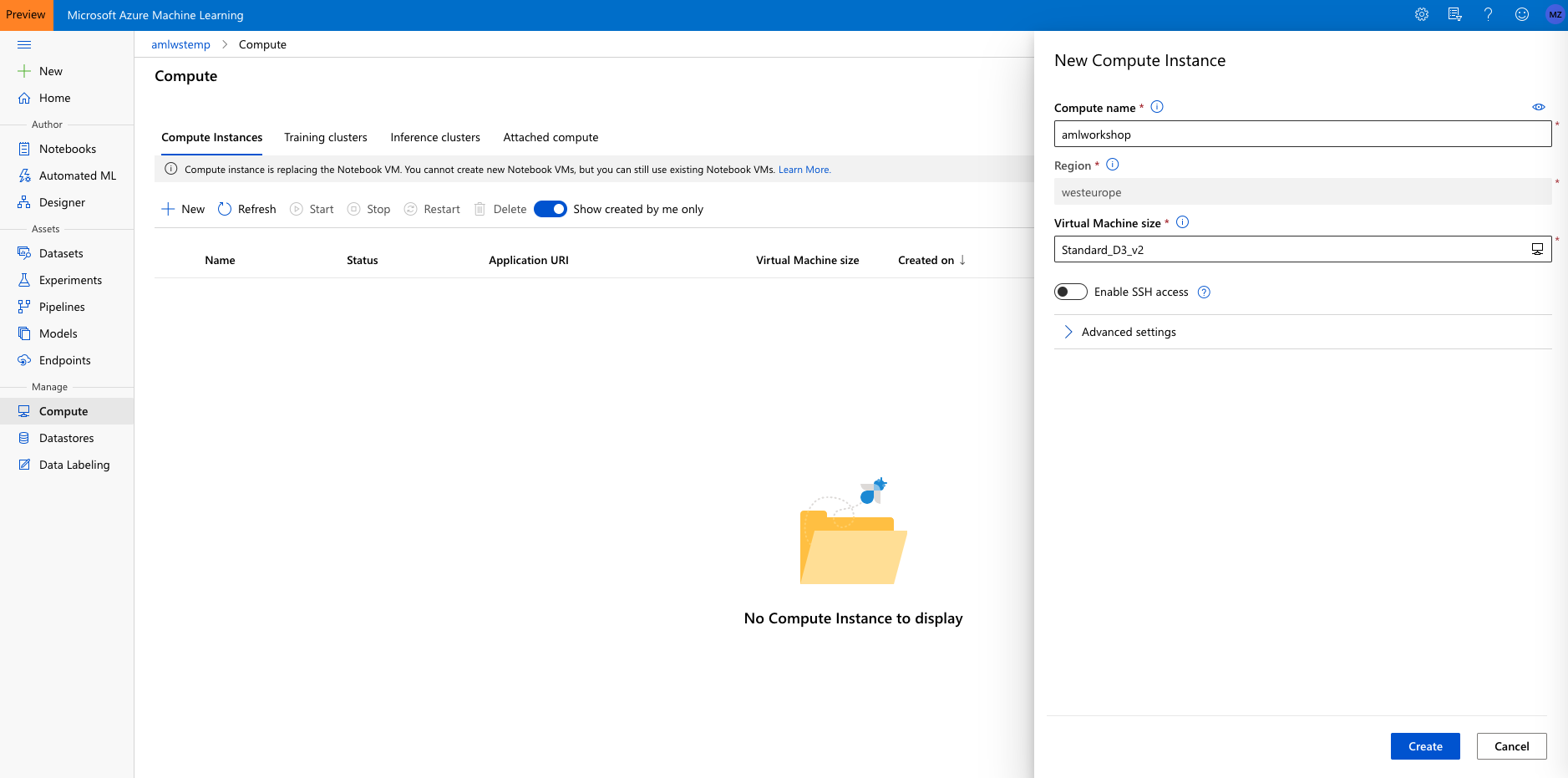
Navigate to ‘Compute Instance’ tab in Compute and click on ‘New’.
-
Choose some sufficiently unique name, keep the default VM type (STANDARD_DS3V2 – a fairly inexpensive machine type costing about $0.27/hour) and click ‘Create’:
See here for details on creating AzureML Compute instances.
Note that this machine will keep running until you stop it from the portal. If you would like to apply an automated shutdown method (see below) follow instructions here

Set up our development environment
Prerequisites
To run through below instructions, you need an Azure subscription and an AzureML workspace. See instructions on how to create a workspace here and more details here.
Clone the Git repository aml-lab-notebooks to the AML Workspace
For the following parts of the workshop, you are going to work on the notebook environment hosted on the Compute instance you just created. First, you need to clone this git repository onto the workspace.
You can either use the:
- Jupyter(Lab) environment or
- AML Workspace Notebook Experience
Option 1 Using Jupyter(Lab)
-
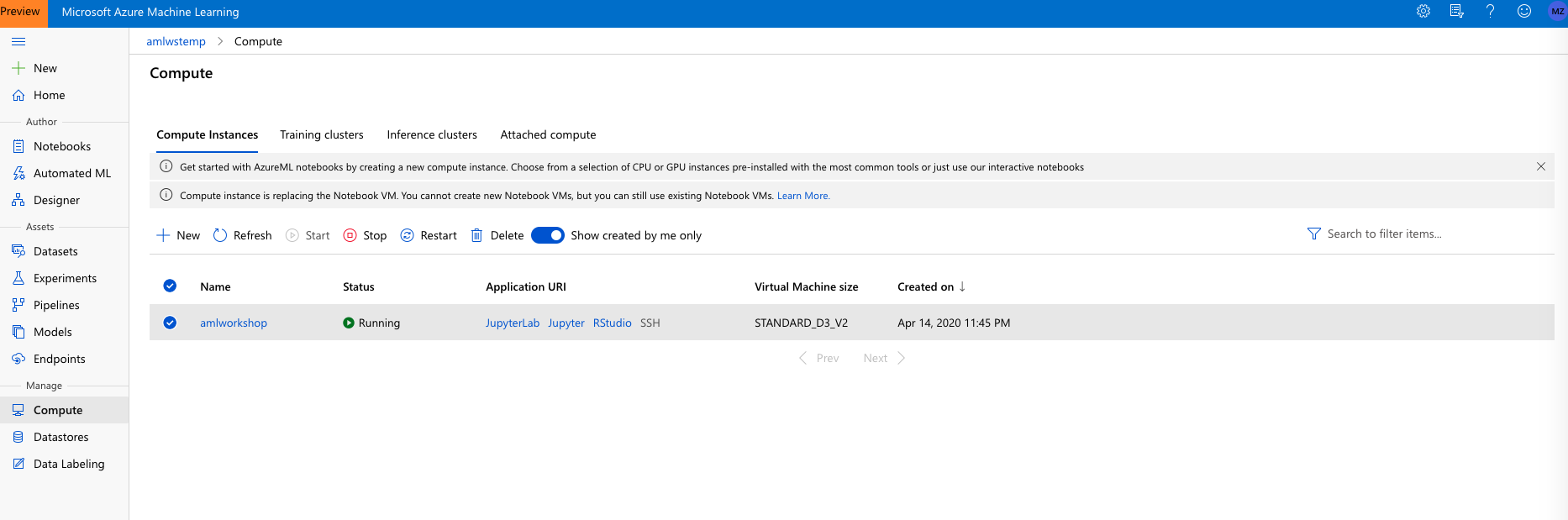
To get started, first navigate to the Jupyter(Lab) instance running on the Compute instance by clicking on the Jupyter(Lab) link shown:
-
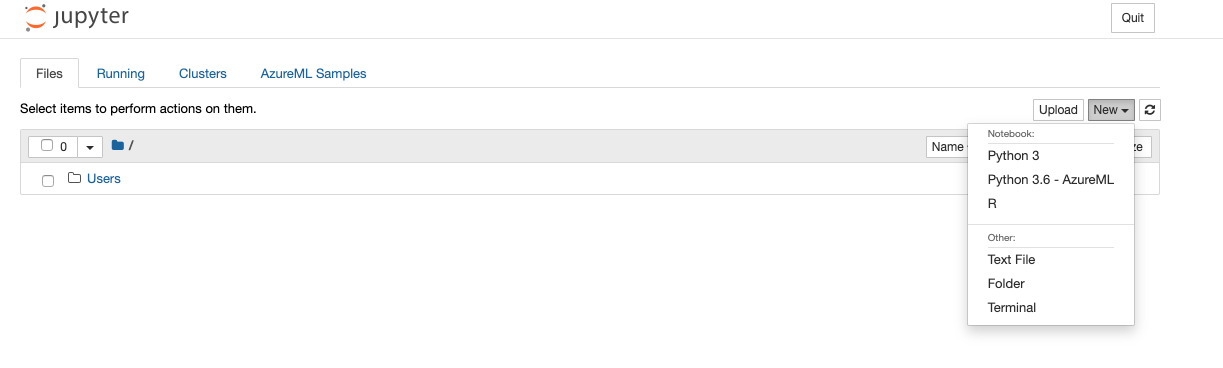
After going through authentication, you will see the Jupyter(Lab) frontend. As you authenticate, make sure to use the same user to log in as was used to create the Compute instance, or else your access will be denied. Next open an Terminal (either by File/New/Terminal, or by just clicking on Terminal from the ‘New’ drop-down menu)

-
In the terminal window clone this repository by typing:
$ git clone https://github.com/Sahiep/aml-lab-notebooks.git
Option 2 Using AML Notebook Experience
-
To get started, first navigate to the Notebooks area in the AzureML Studio:
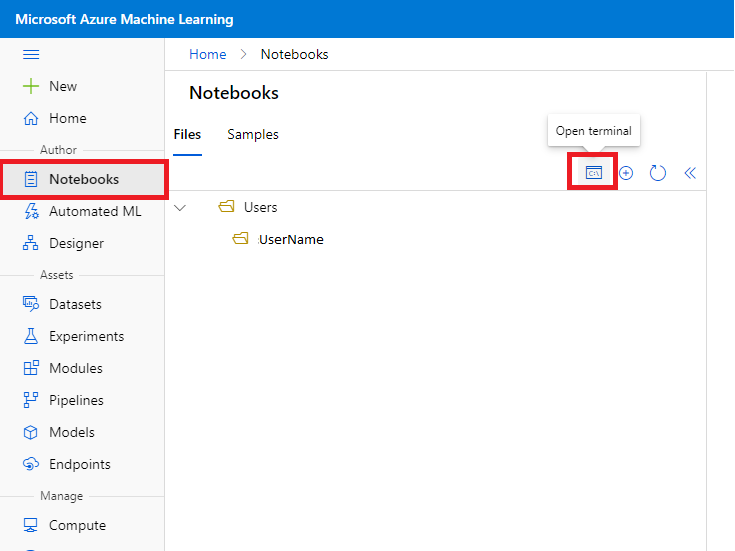
-
Open a new Terminal. Make sure your Compute Instances is selected and in the State “Running”.
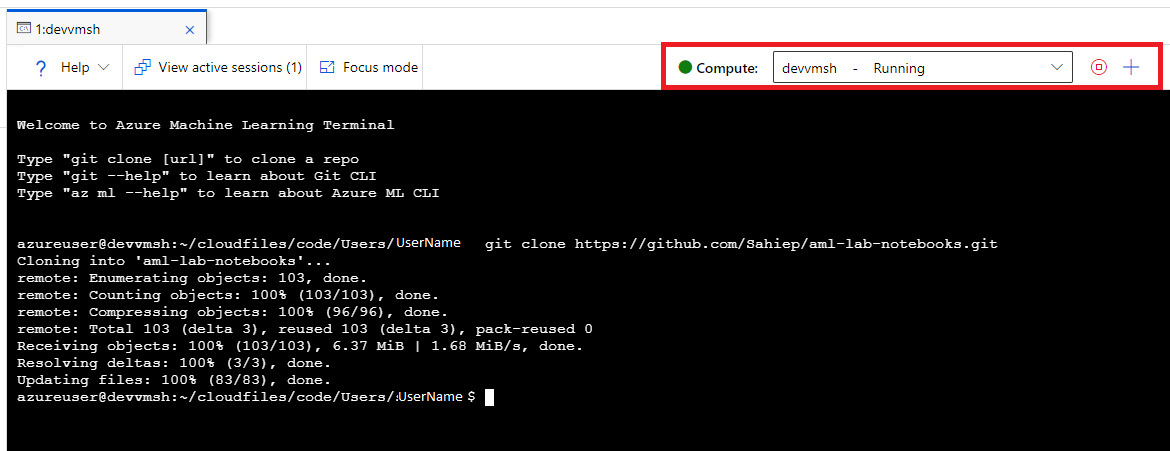
-
In the terminal window clone this repository by typing:
$ git clone https://github.com/Sahiep/aml-lab-notebooks.git
AzureML Datasets
Prerequisites
To run through below instructions, you need an Azure subscription and an AzureML workspace. See instructions on how to create a workspace here and more details here and here.
Create an AML Dataset
AzureML studio allows users to manage their dataset and datastores directly inside the portal.
A Dataset is a resource for exploring, transforming and managing data in Azure Machine Learning. Datasets enable:
-
Easy access to data: without worrying about connection strings or data paths. Only keep a single copy of data in the storage service of your choice.
-
Training with big data: seamless integration with Azure Machine Learning features like labelling, training products and pipelines. Users can share and reuse datasets in various experiments.
-
Tracking data usage: Azure ML automatically tracks which version of the dataset was used for the ML experiment and produced which model.
Option A - Uploading a Dataset to AzureML studio
-
Download the German credit dataset by clicking on this link and saving the file to your local disk
-
Navigate to the left pane of your workspace. Select Datasets under the ‘Assets’ section
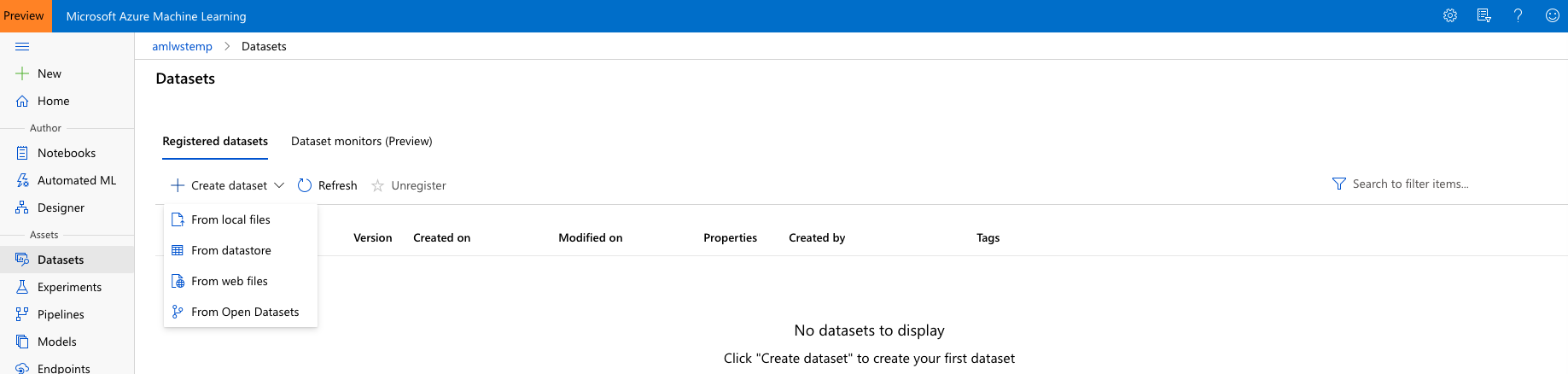
Click on ‘Create dataset’ and choose ‘From local files’. Name the dataset ‘german-credit’ and then click ‘Next’. Make sure to leave the dataset type as Tabular
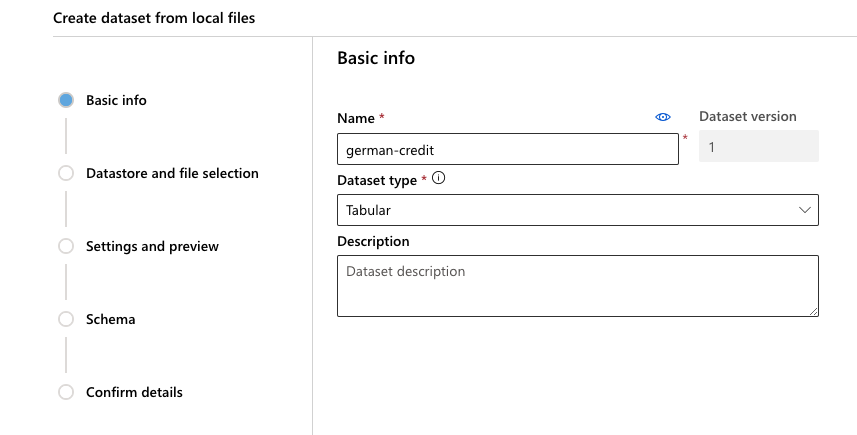
-
Click ‘Upload’, choose the file you had downloaded, and click ‘Next’ to create the dataset in the workspace’s default Blob storage
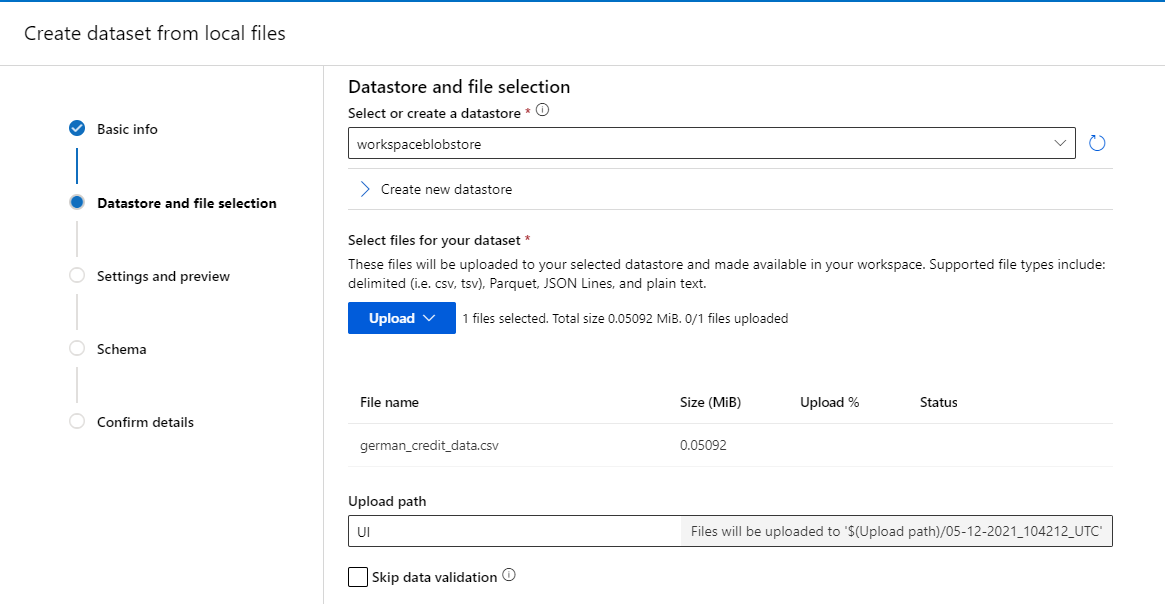
-
Click ‘Next’ through the following “Settings and preview” and “Schema” sections to verify that everything looks correct
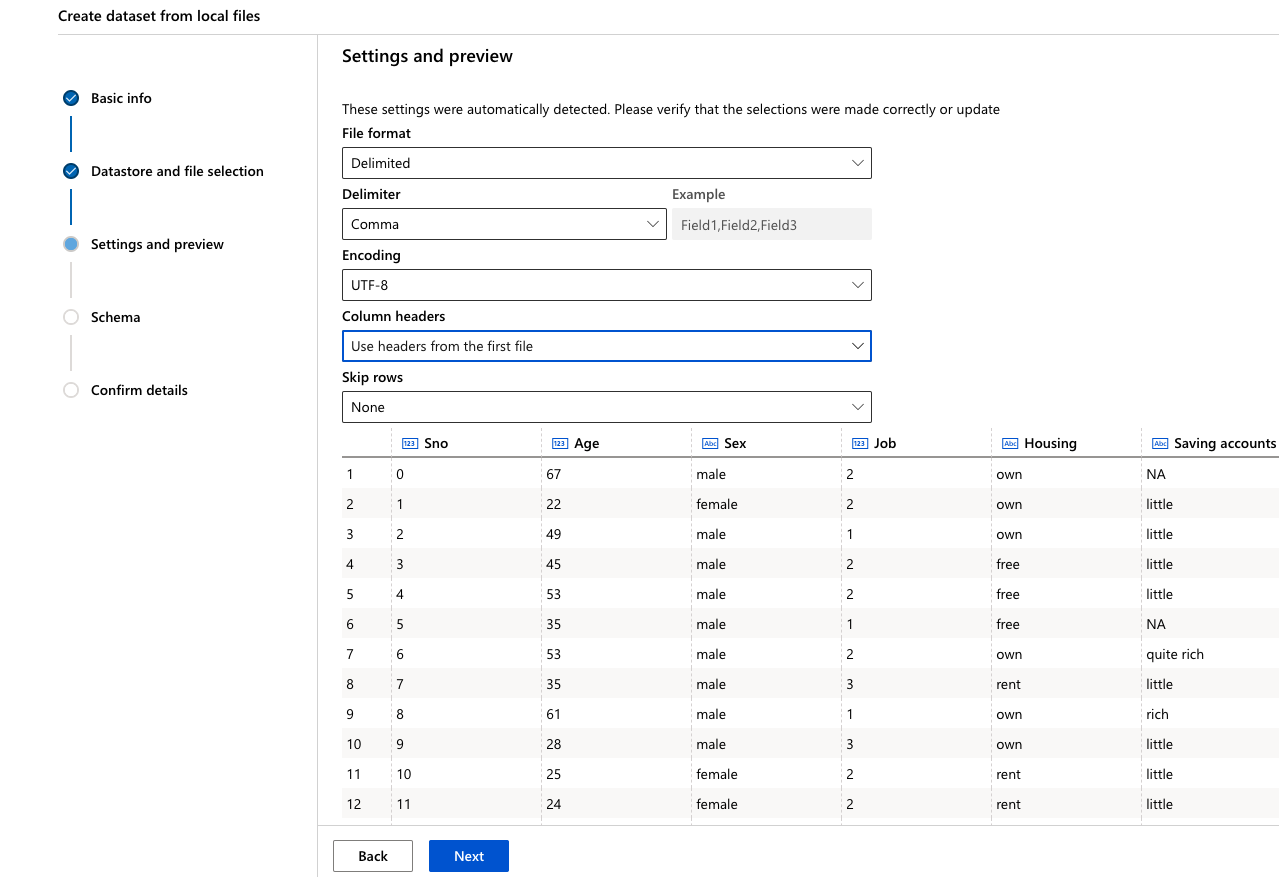
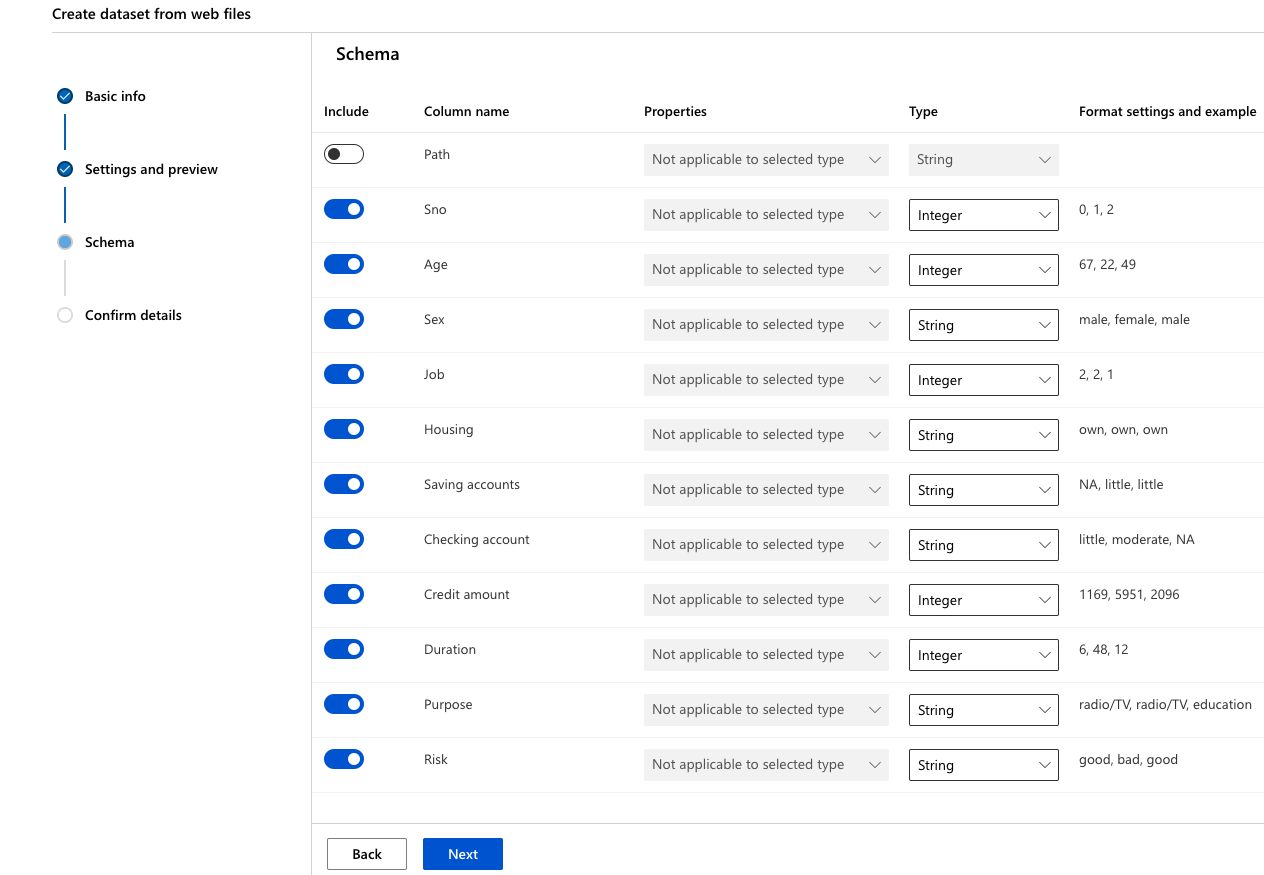
-
Finally, in the “Confirm Details” section, select “Profile this dataset after creation” and specify the ‘cpu-cluster’ that you previously created as the compute to use for profiling and click ‘Create’
Explore the dataset
-
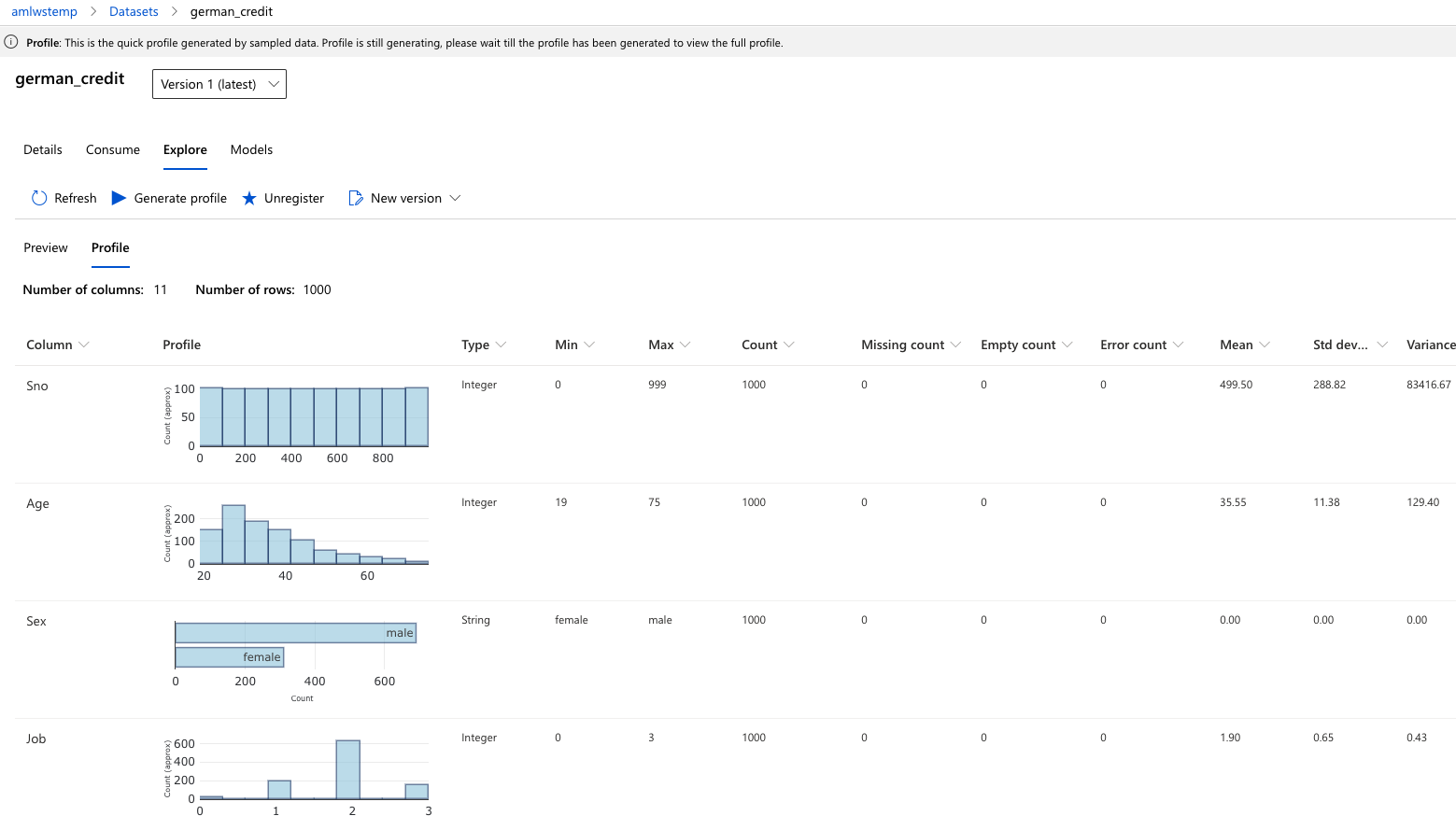
Now, click on the newly created dataset and click ‘Explore’. Here you can see the fields of the Tabular dataset
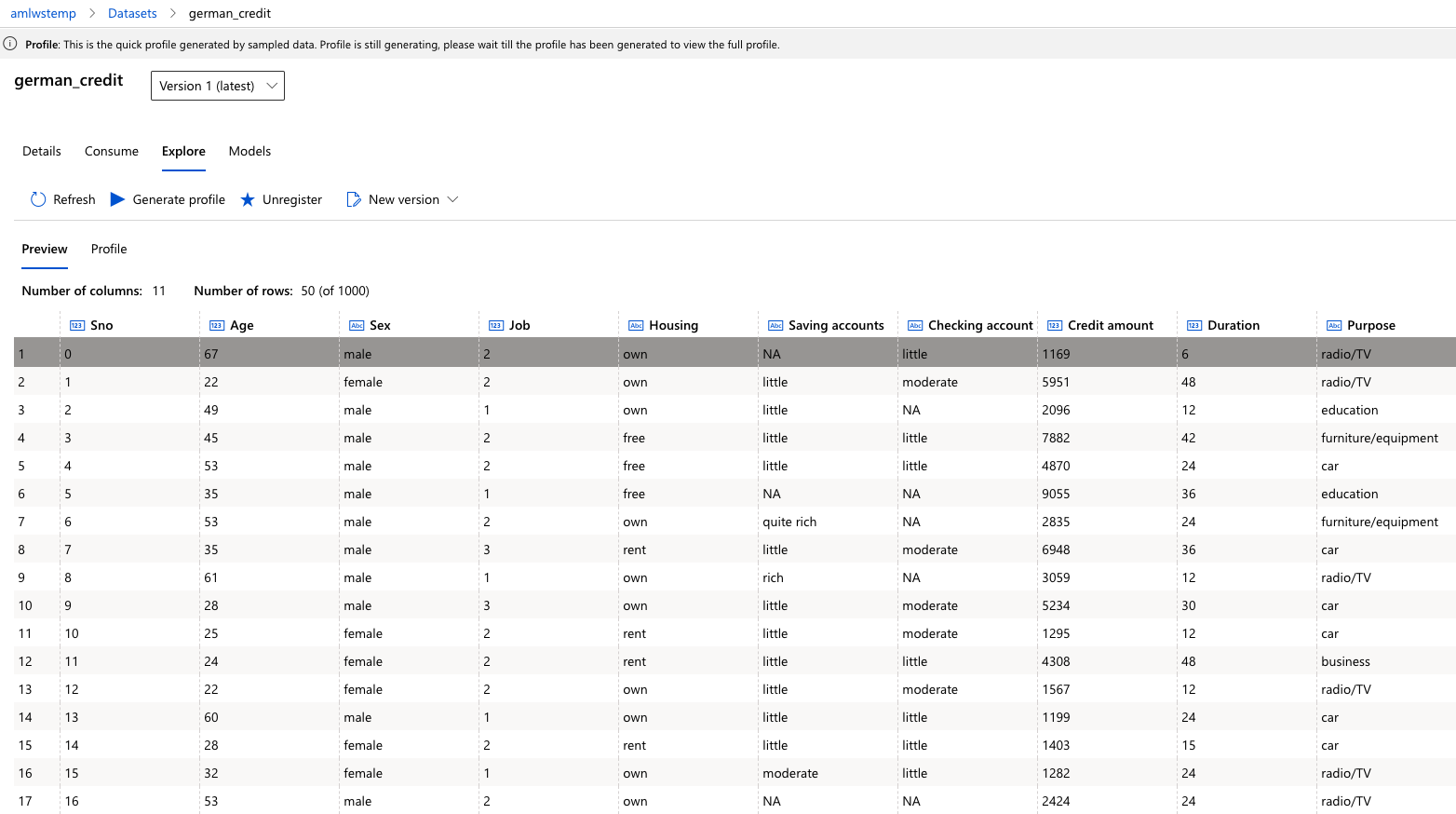
-
To view the profile of the dataset we generated in the previous step, click the “Profile” tab. If you want to regenerate a profile (or you created the dataset without selecting the profile option), you can click “Generate profile” and select a cluster to generate profile information for the dataset
For more information on datasets, see the how-to for more information on creating and using Datasets: https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-create-register-datasets
Option B - Create a Dataset via AzureML SDK
You can also create a Dataset using Python via the AzureML SDK. For more details see here.
To run through below instructions, you need an Azure subscription, AzureML workspace, Compute Instance and the cloned git repository as described above.
- Open the Notebook in the folder aml-lab-notebooks/labs/2_training/Python/1-aml-training-hyperdrive.ipynb an review the first cells on how to connect to your Workspace and Upload Data to a Datastore and register a Dataset.
from azureml.core import Workspace, Datastore, Dataset
# Connect to an existing Azure ML Workshop in order to use Azure ML Datasets and Runs Logging into AML
# if you run this locally download config.json and place it in root folder of the repo
# ws = Workspace.from_config('../../../config.json')
ws = Workspace.from_config()
print(ws.name, ws.resource_group, ws.location, sep='\n')
#Run the following code to determine the datastores in your workspace and upload the files in the folder datasets:
# Get the default datastore
default_ds = ws.get_default_datastore()
# Enumerate all datastores, indicating which is the default
for ds_name in ws.datastores:
print(ds_name, "- Default =", ds_name == default_ds.name)
default_ds.upload(src_dir='../../../../Data/datasets',
target_path='datasets',
overwrite=True)
from azureml.core import Dataset
# Create a tabular dataset from the path on the datastore (this may take a short while)
dataset = Dataset.Tabular.from_delimited_files(path = [(default_ds, './datasets/german_credit_data.csv')])
# preview the first 3 rows of the dataset
dataset.take(3).to_pandas_dataframe()
creditData = dataset.register(workspace = ws,
name = 'german-credit',
description = 'german credit data',
create_new_version = True)